Linux BPF
BPF(Berkeley Packet Filter) 是由 Berkeley 学院于 1992 年开发的一款,主要用于提高抓包工具的性能。并于 2014 年被重写进 Linux 内核中,可以用于 内核观测、网络诊断、性能观测、安全、Kubernetes 网络治理等方面 。 [1]
BPF 是一种灵活且高效的技术实现,主要由 指令集(Instruction Set) 、 存储对象(Storage Objects maps) 和 帮助函数(Helper Functions) 构成。因为其 虚拟指令集规范(Virtual Instruction Set Specification) ,可以认为 BPF 是一个虚拟机,BPF 运行于 内核模式(Kernel Mode) 。BPF 基于事件(Events)运行: Socket Events 、 Tracepoints 、 USDT Probes、kprobes、uprobes、perf_events.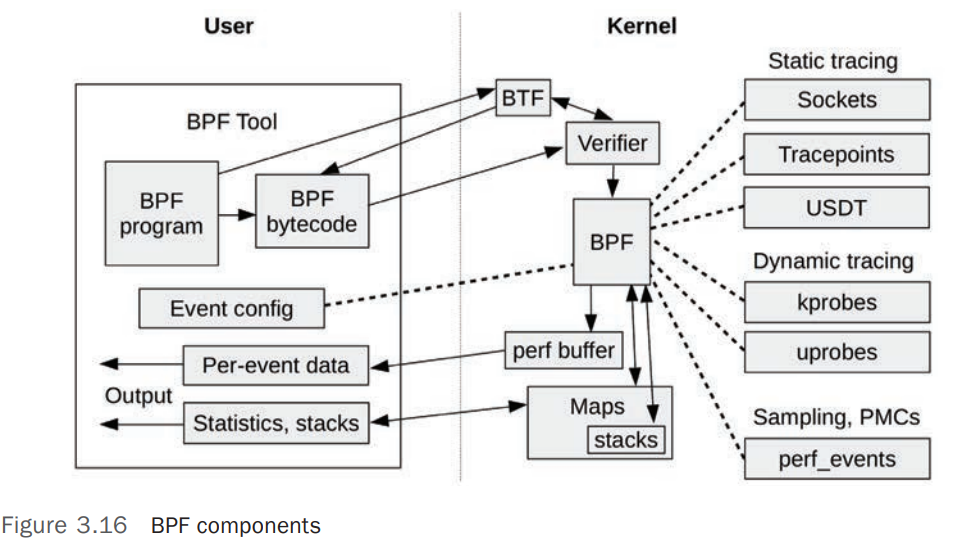
eBPF 允许 :
在运行中的内核里插入自己的逻辑
比如:
- 捕获 TCP 连接
- 统计进程系统调用
- 跟踪磁盘 IO
- 分析网络延迟
- 拦截数据包
而且:
无需修改内核源码,只在内核事件点插入逻辑,无需重启系统,是 Linux 内核的动态扩展机制
这是 eBPF 最核心的价值。
eBPF 基础原理
eBPF 本质 运行在 Linux 内核中的事件驱动程序 。关键点:
- 运行在 内核空间(Kernel Space)
- 事件驱动(Event),不会一直运行,只有在 某个事件(Event)发生时,才会运行
eBPF = Hook + Event + Action
eBPF 的完整执行流程
eBPF 的执行流程分六步
编写 eBPF 程序 。例如 把程序挂到
tcp_connect函数上SEC("kprobe/tcp_connect")
int trace_tcp() {
return 0;
}编译为 BPF Bytecode(eBPF 虚拟机字节码) 。eBPF 运行的不是机器码,而是 BPF 字节码
clang -> BPF bytecode
加载到内核 。用户态程序通过
bpf()系统调用,把字节码加载进内核。Verifier 验证程序安全 ,这是 eBPF 最重要的机制,用户把程序加载到内核,是极其危险的,它会检查
- 是否有非法内存访问
- 是否有无限循环
- 是否可能访问非法指针
- 其他危险操作
Attach:把程序挂到事件点 。程序通过 verifier 后,要挂到某个 Hook 点 (Event),比如
kprobe:tcp_connect,每次调用tcp_connect,就执行 eBPF 程序tracepoint:sys_enter_execve,每次进程执行时触发XDP,挂到网卡驱动层本质是: Attach = 指定“什么时候执行 eBPF” 。这是 eBPF 的事件驱动核心。
事件发生时,程序运行
Map
Map 是内核(Kernel)与用户态(User Space)之间的通信机制 。eBPF 程序运行在内核,但它不能直接:
- print 到终端
- 写文件
所以必须通过 BPF Map 与用户态交换数据。其本质是内核中的 Key-Value 存储。eBPF 程序更新 Map,用户态读取 Map。 Map 是用户态和内核态共享数据桥梁
Hook 点
Hook 点是在内核执行路径中插入的一个触发点或者说在内核某个位置插入 eBPF 程序 。正常内核流程:
事件发生 -> 内核函数执行 |
加上 eBPF 后:
事件发生 -> Hook 点 -> eBPF 程序执行 -> 原逻辑继续 |
不同 Hook 点,看到的数据不同,性能不同,用途不同
- Hook 在系统调用入口,可以观察 哪个进程调用了
open()、execve()等函数,适合 进程行为观测 - Hook 在网络包入口,可以观察: 收到哪个数据包、包头是什么,适合 网络过滤 / DDoS 防护
- Hook 在用户程序函数,可以观察:应用函数调用、函数耗时,适合 应用性能分析
所以: Hook 点 = eBPF 能看到什么、能做什么
eBPF 最重要的五类 Hook 点
- kprobe ,挂到内核函数,把 eBPF 程序挂到任意的某个内核函数入口,比如
tcp_connect。因为挂在函数入口,所以常用于:- 获取函数参数,比如
tcp_connect(sock, addr)拿到: socket 信息、目标地址 - 统计调用次数
- 统计执行耗时
kprobe 用于跟踪内核函数行为 。优点是非常灵活,能挂任意内核函数;缺点是依赖内核函数名,不稳定(不同内核版本可能变),内核升级可能导致 kprobe 失效
- 获取函数参数,比如
- tracepoint ,挂到内核预定义的稳定事件点。 因为 tracepoint 是 Linux 官方定义接口,相比 kprobe 不会轻易变,跨内核版本更稳定
- uprobes ,把 eBPF 程序挂到用户态程序函数,如 Nginx、Mysql 等。主要用于 应用程序性能分析
- XDP ,挂到网卡驱动(收包入口)层。XDP 在最早的网络入口处理包,是 Linux 网络性能天花板,Cilium 就是基于 XDP 实现。
- TC ,Linux 流量控制(Traffic Control)层。XDP 是网卡驱动层,性能更高。TC 是 Linux 内核网络层,功能更多,更适合复杂网络策略。
bpftrace
bpftrace 是一个基于 BPF 的追踪工具(Trace Tools),提供了高级别的编程能力,同时包含了命令行和脚本使用方式
bpftrace 命令行
bpftrace 命令详细帮助文档请查看 man bpftrace,下表列出常用选项和参数
| 选项 | 说明 | 示例 |
|---|---|---|
-l [SEARCH] |
列出匹配的事件(Event/Probe),没有 SEARCH 表达式则列出所有的 Event。SEARCH 支持通配符 |
|
-e 'program' |
跟踪脚本 |
筛选指定的事件
bpftrace -l "tracepoint:*exec*" |
跟踪新启动的进程
执行以下命令,可以追踪系统中新启动的进程及其参数
bpftrace -e 'tracepoint:syscalls:sys_enter_execve { join(args->argv); }' |
参考链接
Systems Performance: Enterprise and the Cloud v2
脚注
- 1.Systems Performance: Enterprise and the Cloud v2 #3.4.4 Extended BPF ↩