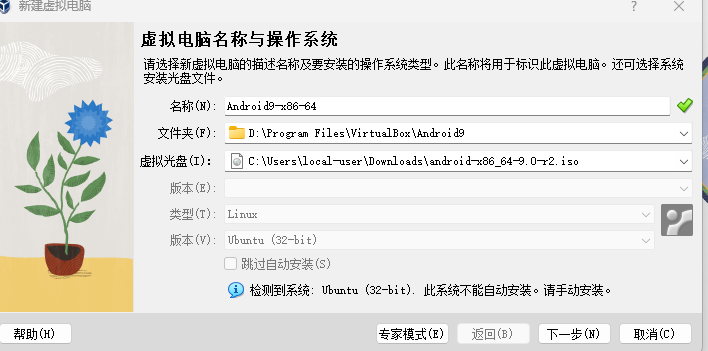
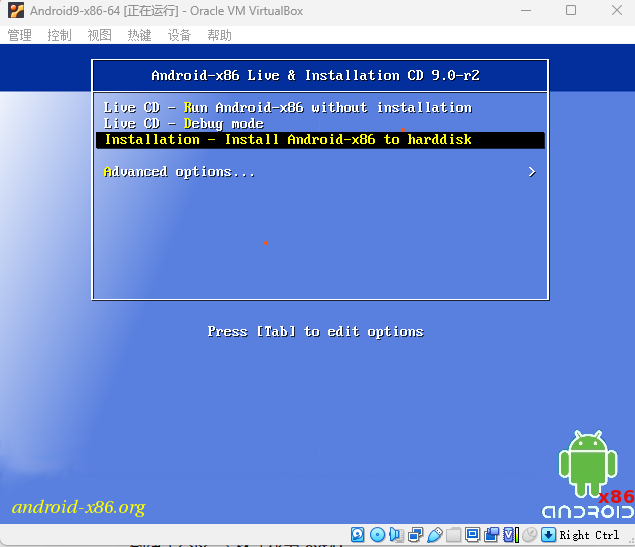
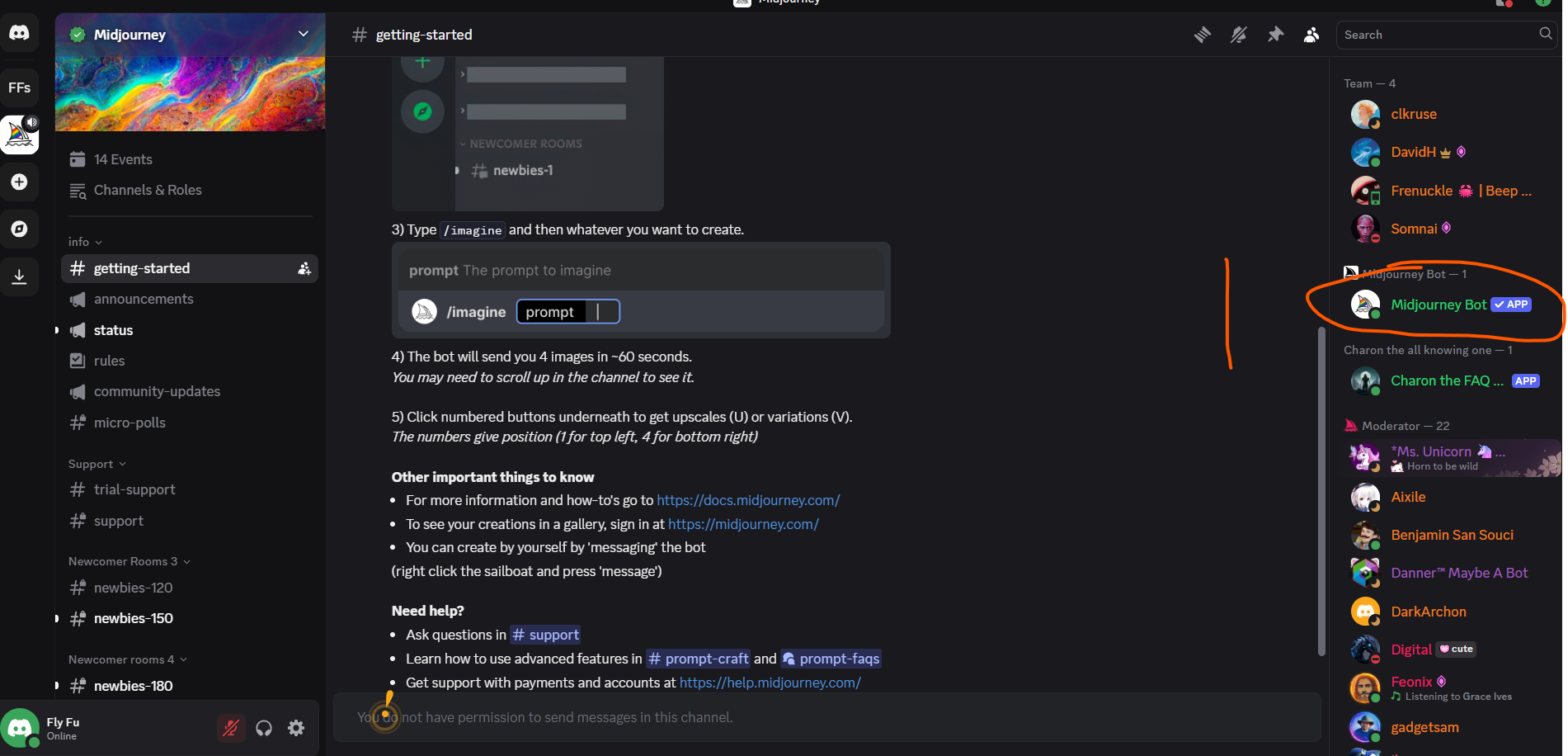
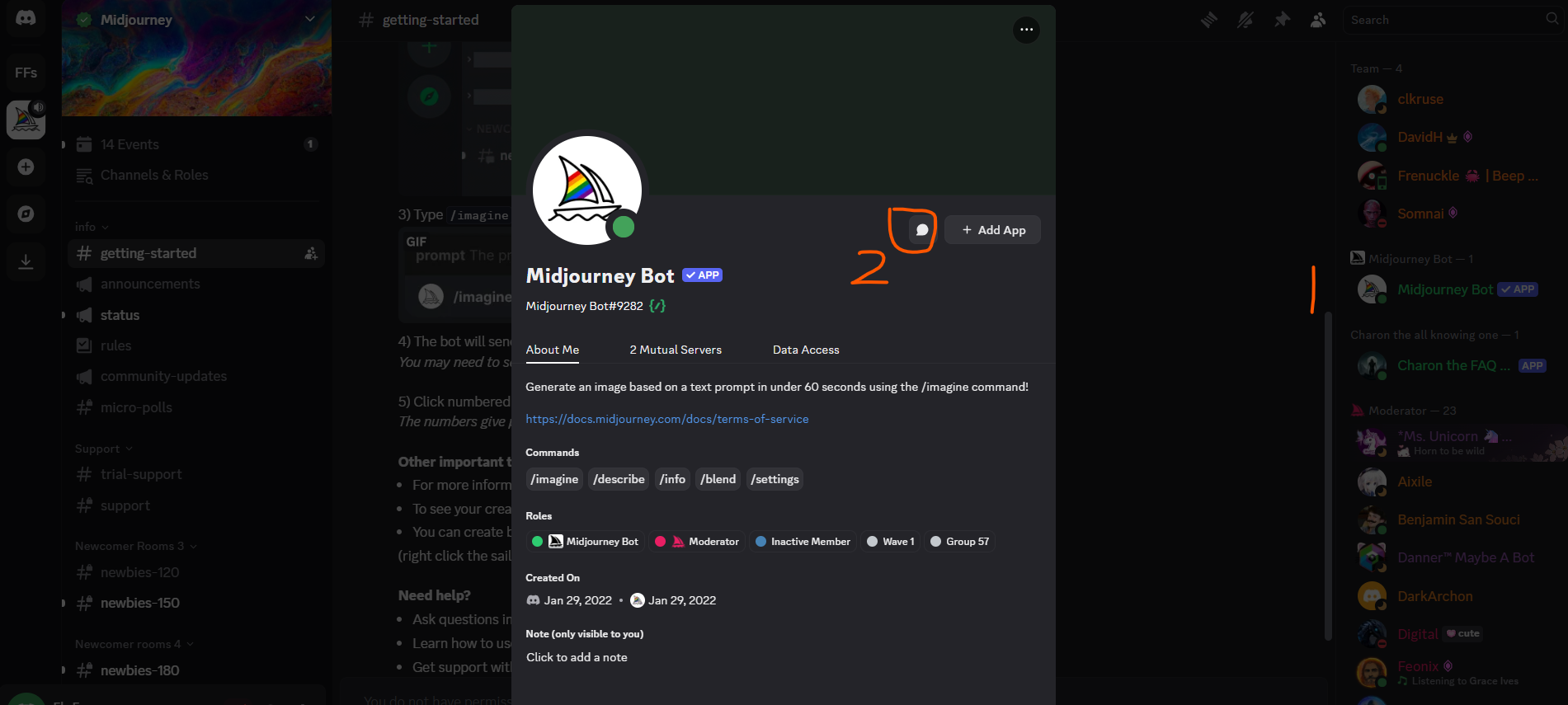
首先在 Windows/MacOS/Linux 系统中安装 Charles Proxy 软件,并开启代理抓包。
在 MUMU 模拟器中安装目标 APP
在 MUMU 模拟器中为系统配置代理
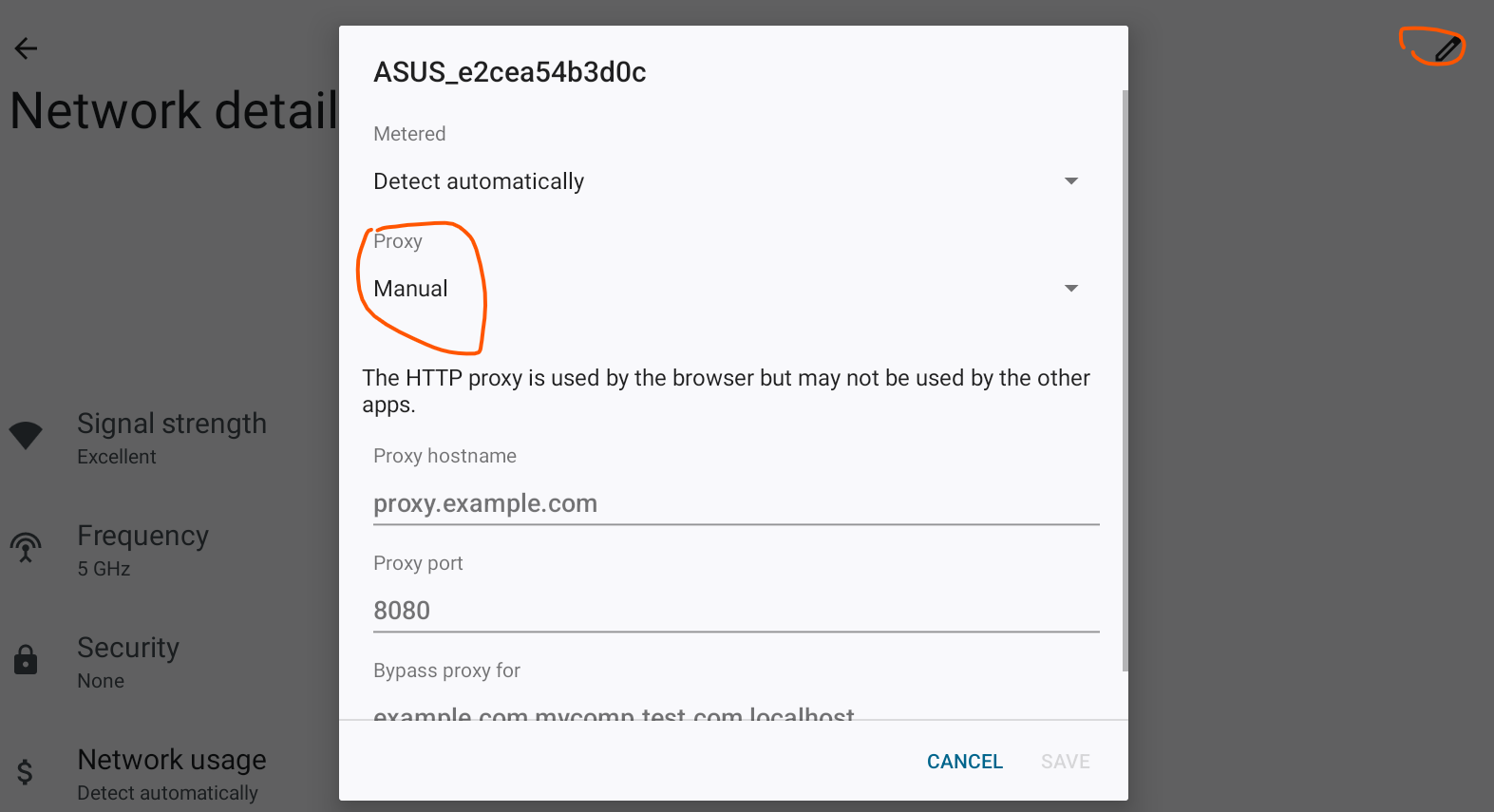
在 Settings --> Network & Internet --> Internet --> WiFi 中选择目标网络
选择目标网络右侧的 配置按钮,点击右上角的 修改 。
Proxy 模式选择 Manual,并填入 Charles Proxy 的 IP 和 端口
在 MUMU 模拟器中打开 APP ,在 Charles 中检查是否捕获到了对应的流量
Charles 需要开启 SSL Proxying 才能解密 HTTPS 流量。
在 Charles 中,确保已经启用 SSL Proxying :
进入 Proxy > SSL Proxying Settings
确保勾选了 Enable SSL Proxying 。
然后在 Add 按钮中,确保已经添加了所有请求的域名和端口(可以选择 * 来捕获所有域名和端口)。
确保端口是 443(HTTPS 默认端口)。
查看 Charles 证书并在客户端安装 Charles 证书
在 Charles 的菜单 Help --> SSL Proxying --> Install Charles Certificates on a mobile device 会展示如何获取到 Charles 证书,通常是在已经设置了代理的终端通过链接 http://charlesproxy.com/getssl 下载证书。下载后在 MUMU 模拟器的 Settings --> Network & Internet --> Internet --> Network preferences --> install certificates 中安装已经下载的证书
$ openssl rand -base64 Usage: rand [options] num where options are -out file - write to file -engine e - use engine e, possibly a hardware device. -rand file:file:... - seed PRNG from files -base64 - base64 encode output -hex - hex encode output
# etcd {"level":"warn","ts":"2023-10-05T02:16:52.853273Z","caller":"embed/config.go:673","msg":"Running http and grpc server on single port. This is not recommended for production."} {"level":"info","ts":"2023-10-05T02:16:52.853914Z","caller":"etcdmain/etcd.go:73","msg":"Running: ","args":["etcd"]} {"level":"warn","ts":"2023-10-05T02:16:52.853947Z","caller":"etcdmain/etcd.go:105","msg":"'data-dir' was empty; using default","data-dir":"default.etcd"} {"level":"warn","ts":"2023-10-05T02:16:52.853994Z","caller":"embed/config.go:673","msg":"Running http and grpc server on single port. This is not recommended for production."} {"level":"info","ts":"2023-10-05T02:16:52.854009Z","caller":"embed/etcd.go:127","msg":"configuring peer listeners","listen-peer-urls":["http://localhost:2380"]} ...
常用管理命令
etcd
查看版本信息
# etcd --version etcd Version: 3.5.3 Git SHA: 0452feec7 Go Version: go1.16.15 Go OS/Arch: linux/amd64